Здравствуйте. Настраиваю Парсер контента от dwd.
Изучил мануал http://codeplace.ru/manual/sozdanie-saitov/sistemy-upravlenija-saitom-cms/instantcms-2-parser-kontenta.html
и соотвественно посмотрел видео обучение.
Вот ссылка, от куда я стараюсь добавить задачу на парсинг, новость с которой беру код из текста: https://belnaviny.by/proishestviya/v-minske-muzhchina-vygulival-sobaku-i-napal-na-milicionera.html
Общие настройки сделал (кажется), так же смог найти заголовок и анонс. Но, так как в коде я не сильно силен, уже несколько часов застрял на тестере стратегий поиска на странице изображения и текста статьи.
Вот начало и конец искомого текста заголовка новости:
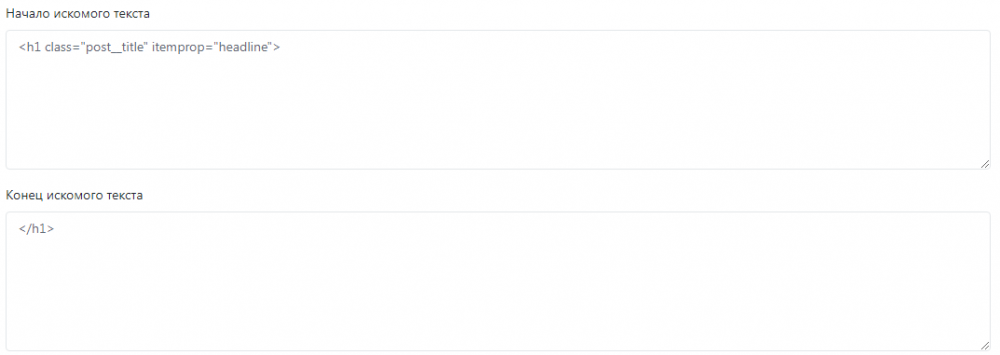
Вот начало и конец искомого текста анонса новости
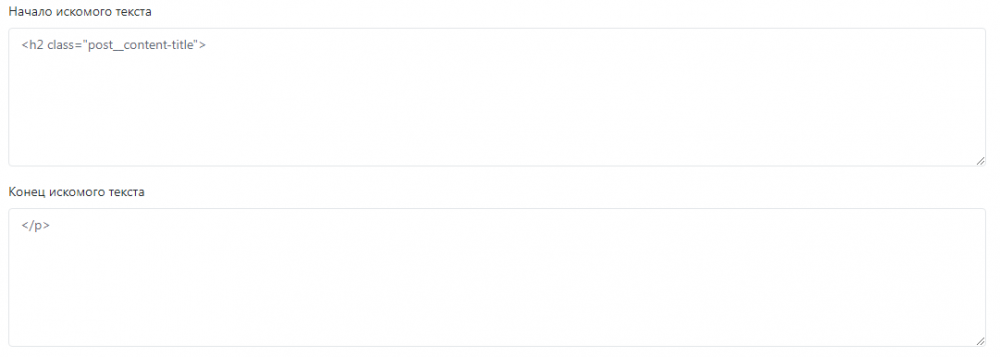
В тестере стратегий, заголовок и анонс показывает так как в донорской новости.
Но когда я беру изображение, как бы ни искал код начала и конца картинки, всегда показывает ее с какими то ошибками или с лишней информацией.
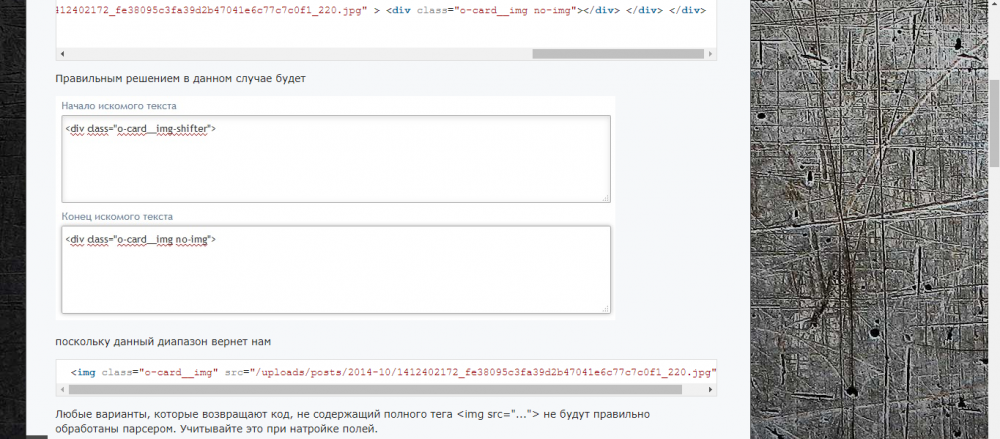
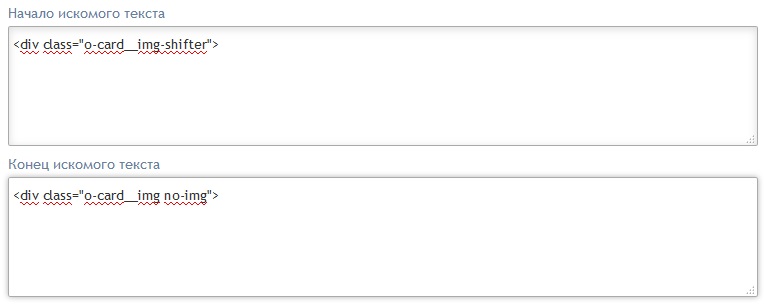
Вот на пример начало и конец искомого текста для изображения :
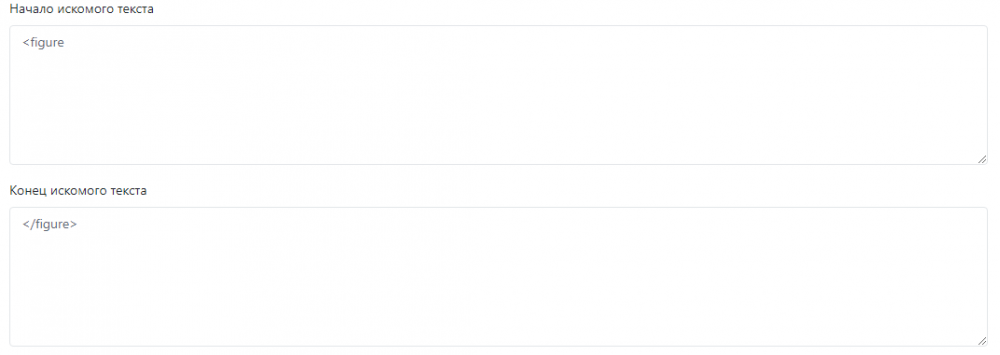
И всегда получается либо код лишний показывает, либо вообще ничего:
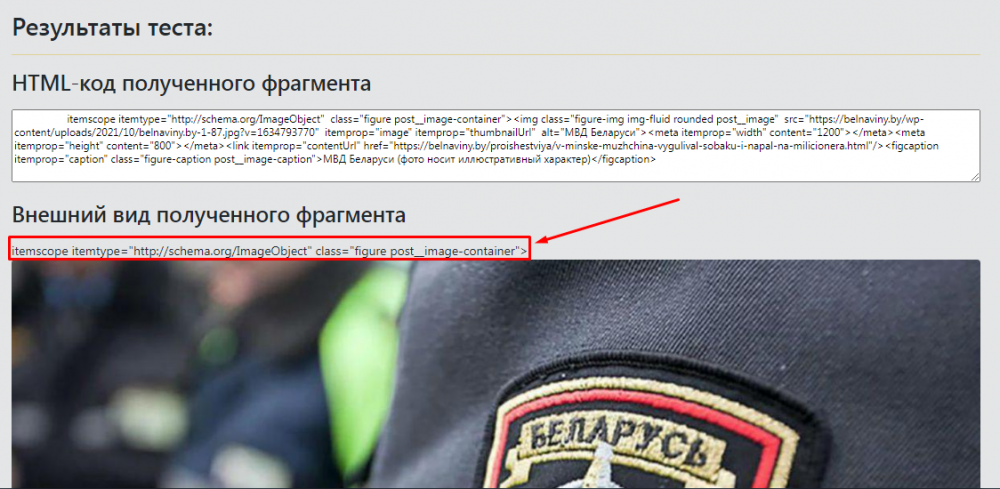
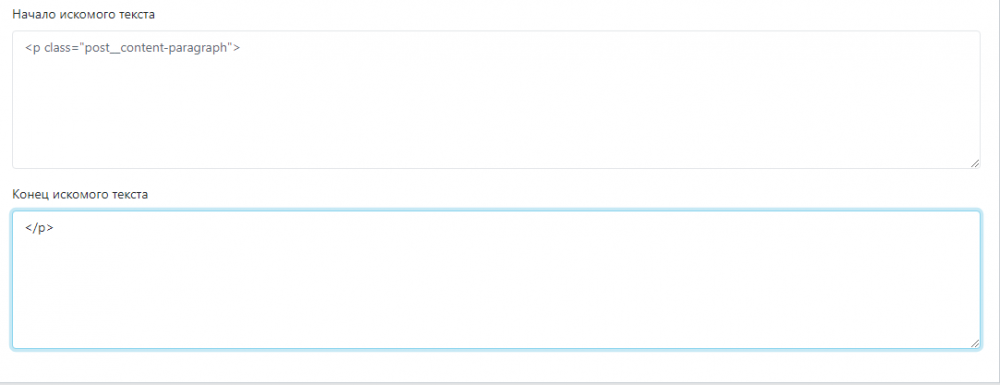
Так же и с текстом новости, ну не могу я понять как взять именно текст самой новости

Беру на пример начало и конец искомого текста, и ничего не найдено, либо что то еще пробую, показывает анонс новости.
Подскажите пожалуйста на пальцах, что именно я делаю не так? Хочется самому разобраться.